ChatGPT 誕生的第二年,OpenAI 和國(guó)內(nèi)的一眾企業(yè)正在試著 " 拋棄 " 它。
在 Scaling Law 被質(zhì)疑能力 " 見頂 " 的情況下,今年 9 月,OpenAI 帶著以全新系列命名的模型 o1 一經(jīng)發(fā)布," 會(huì)思考的大模型 " 再度成為焦點(diǎn)。
" 我認(rèn)為這次 o1 模型發(fā)布最重要的信息是,AI 發(fā)展不僅沒有放緩,而且我們對(duì)未來幾年已經(jīng)勝券在握。" 對(duì)于 o1 的發(fā)布,奧特曼信心滿滿。
國(guó)內(nèi)大模型廠商對(duì) o1 的學(xué)習(xí)、超越任務(wù)也提上了日程。兩個(gè)多月之后,國(guó)內(nèi)大模型公司紛紛效仿,相繼推出了各具特色的 o1 類深度思考模型。
無論是 kimi 的 k0 math、Deepseek 的 DeepSeek-R1-Lite,還是昆侖萬維推出的 " 天工大模型 4.0"o1 版,都在強(qiáng)調(diào)著國(guó)內(nèi)大模型對(duì)大模型邏輯思考能力的重視。
國(guó)產(chǎn)大模型集體跟進(jìn) o1
在 OpenAI 沒有披露 o1 具體技術(shù)的情況下,只用了 2 個(gè)月左右的時(shí)間,國(guó)內(nèi)大模型公司就跟上了前沿方向的能力:
11 月 16 日,月之暗面在發(fā)布會(huì)上公開了新模型 k0 math,通過采用強(qiáng)化學(xué)習(xí)和思維鏈推理技術(shù),大模型開始試圖模擬人類的思考和反思過程,從而增強(qiáng)其數(shù)學(xué)推理能力。顧名思義,它在研究數(shù)學(xué)難題方面的能力可謂 " 遙遙領(lǐng)先 "。
4 天后,Deepseek 的 DeepSeek-R1-Lite 正式上線。和 OpenAI 的 o1 相比,R1 毫無保留地放出了大模型思考的完整過程。官方表示,R1 的思維鏈長(zhǎng)度可達(dá)數(shù)萬字。從官方測(cè)試結(jié)果來看,在 AIME(美國(guó)數(shù)學(xué)競(jìng)賽)、部分編程比賽的測(cè)試上,R1 的表現(xiàn)超越了 o1-Preview。Deepseek 還直接在官網(wǎng)放出了測(cè)試版,允許用戶每天體驗(yàn) 50 次對(duì)話。
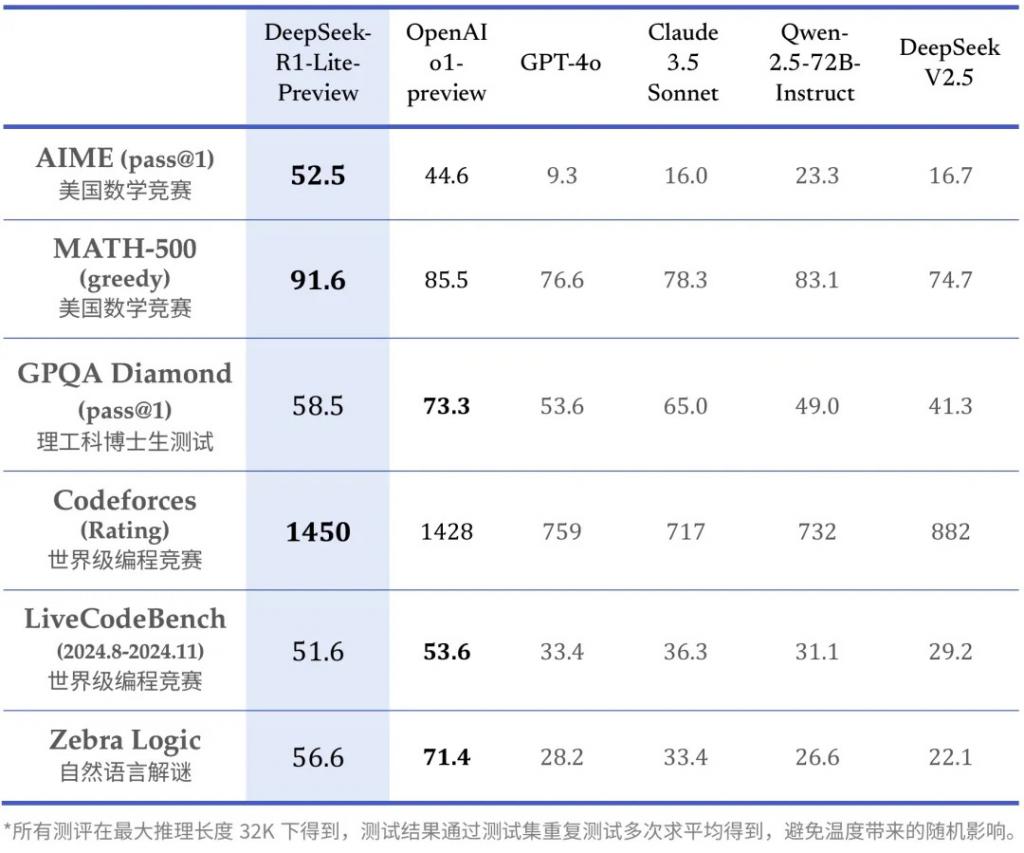 就在上周三(11 月 27 日),昆侖萬維也放出了具有復(fù)雜思考推理能力的天工大模型 4.0 o1 版(Skywork o1),宣布它是國(guó)內(nèi)首款實(shí)現(xiàn)中文邏輯推理的模型。它也一次性給出了三種模型版本:開源的 Skywork O1 Open、優(yōu)化中文支持能力的 Skywork O1 Lite,以及完整展現(xiàn)模型思考過程的 Skywork O1 Preview。
就在上周三(11 月 27 日),昆侖萬維也放出了具有復(fù)雜思考推理能力的天工大模型 4.0 o1 版(Skywork o1),宣布它是國(guó)內(nèi)首款實(shí)現(xiàn)中文邏輯推理的模型。它也一次性給出了三種模型版本:開源的 Skywork O1 Open、優(yōu)化中文支持能力的 Skywork O1 Lite,以及完整展現(xiàn)模型思考過程的 Skywork O1 Preview。
扎堆涌現(xiàn)的國(guó)產(chǎn) "o1" 大模型們,不想只做簡(jiǎn)單的 " 模型復(fù)刻 "。
從模型測(cè)試跑出的指標(biāo)分?jǐn)?shù)來看,上述模型在數(shù)學(xué)、代碼等能力上的表現(xiàn)均逼近、甚至超過了 o1:
以 k0 math 為例,在中考、高考、考研以及包含入門競(jìng)賽題的 MATH 等 4 個(gè)數(shù)學(xué)基準(zhǔn)測(cè)試中,k0-math 的成績(jī)超過了 OpenAI 的 o1-mini 和 o1-preview 模型。
不過,在一些難度更大的競(jìng)賽測(cè)試題能力表現(xiàn)上,比如難度更大的競(jìng)賽級(jí)別的數(shù)學(xué)題庫(kù) OMNI-MATH 和 AIME 基準(zhǔn)測(cè)試中,ko math 表現(xiàn)還沒辦法趕上 o1-mini。
能夠做出難度高的數(shù)學(xué)題,類 o1 的大模型們開始學(xué)會(huì)了 " 慢思考 "。
通過在模型中引入思維鏈(CoT),大模型將復(fù)雜問題拆解為多個(gè)小問題,開始模擬人類逐步推理的過程。這是在無人參與的情況下,由大模型獨(dú)立完成推理。強(qiáng)化學(xué)習(xí)使大模型能夠自行嘗試多種不同的解題方法并根據(jù)反饋調(diào)整策略,學(xué)習(xí)和反思的任務(wù)的任務(wù),都交給了大模型。
和一般模型相比,此類產(chǎn)品在一些往常無法解決的問題上也能夠正確回答,比如 " 草莓 strawberry" 一共有幾個(gè) r、"9.11 和 9.9 相比哪個(gè)大 " 等問題,交給 o1,它能在一番思考后給出正確的答案。
 比如,把 "Responsibility 中有幾個(gè)字母 i?" 的問題拋給 Deepseek R1,在深度思考模式中,我們能夠看到大模型的思考過程:它先把單次拆解成一個(gè)個(gè)字母,再逐步比較每個(gè)字母是什么,最終給出了正確的結(jié)果。在測(cè)試中,R1 的思考速度也夠快,用不到兩秒的時(shí)間給出了答案。
比如,把 "Responsibility 中有幾個(gè)字母 i?" 的問題拋給 Deepseek R1,在深度思考模式中,我們能夠看到大模型的思考過程:它先把單次拆解成一個(gè)個(gè)字母,再逐步比較每個(gè)字母是什么,最終給出了正確的結(jié)果。在測(cè)試中,R1 的思考速度也夠快,用不到兩秒的時(shí)間給出了答案。
 專精還是空中樓閣,o1 的硬幣兩面
專精還是空中樓閣,o1 的硬幣兩面
批量制造的 " 慢思考 " 大模型們,在強(qiáng)化學(xué)習(xí)和邏輯鏈的加成下,模型能力的表現(xiàn)突飛猛進(jìn)。
在 Deepseek 公布的測(cè)試效果中,可以看到,DeepSeek-R1-Lite 的推理時(shí)間和準(zhǔn)確率成正比關(guān)系,即推理時(shí)長(zhǎng)越長(zhǎng),跑出的效果就越好。和過往沒有 " 慢思考 " 能力的模型相比,R1 的表現(xiàn)遠(yuǎn)優(yōu)于前者。
 在上述能力的加成下,大模型的自我反思、學(xué)習(xí)能力提升明顯。比如,面對(duì)陷阱時(shí),模型可以通過思維鏈模式自行避開問題。
在上述能力的加成下,大模型的自我反思、學(xué)習(xí)能力提升明顯。比如,面對(duì)陷阱時(shí),模型可以通過思維鏈模式自行避開問題。
發(fā)布自研模型時(shí),昆侖萬維給了大模型一個(gè) " 陷阱 " 題目。讓它回答存在中文讀音 " 陷阱 " 的問題—— " 請(qǐng)將 qíng rén y ǎ n l ǐ ch ū x ī sh ī 轉(zhuǎn)換為中文 "。在第一次思考得出結(jié)論時(shí),大模型主動(dòng)發(fā)現(xiàn)了 " 西詩 " 是不對(duì)的說法,通過推理找到了準(zhǔn)確的翻譯結(jié)果。
 一方面,慢思考模型大幅提升了大模型在一些特定學(xué)科上的表現(xiàn),解決難題的能力進(jìn)一步提升;另一方面,大量耗費(fèi) tokens 的方式卻未必能換來用戶需要的回報(bào),這也是常被用戶詬病的一點(diǎn)。
一方面,慢思考模型大幅提升了大模型在一些特定學(xué)科上的表現(xiàn),解決難題的能力進(jìn)一步提升;另一方面,大量耗費(fèi) tokens 的方式卻未必能換來用戶需要的回報(bào),這也是常被用戶詬病的一點(diǎn)。
在某些情況下,增加模型思維鏈的長(zhǎng)度可以提高效率,因?yàn)槟P湍軌蚋钊氲乩斫夂徒鉀Q問題。
然而,這并不意味著它在所有情況下都是最優(yōu)解。
比如,思考 "1+1>2" 這類常識(shí)性問題,顯然從效率和成本上來看,更適合用以往大模型的能力。這就需要大模型學(xué)會(huì)對(duì)問題難度自行進(jìn)行判別,從而決定是否采用深度思考模式回答對(duì)應(yīng)問題。
而在科學(xué)研究或復(fù)雜項(xiàng)目規(guī)劃中,增加思維鏈的長(zhǎng)度可能是有益的。在這些情況下,深入理解各個(gè)變量及其相互作用,對(duì)于制定有效的策略和預(yù)測(cè)未來的結(jié)果至關(guān)重要。
此外,從特定場(chǎng)景下的強(qiáng)化學(xué)習(xí)應(yīng)用轉(zhuǎn)向通用模型,在訓(xùn)練算力和成本的平衡上或許還有一定難度。
從國(guó)內(nèi)發(fā)布的模型來看,目前 " 慢思考 " 類大模型開發(fā)的基座模型參數(shù)不大。比如 Deepseek 和昆侖萬維給出的模型版本,都建立在規(guī)模量更小的模型上:Skywork o1 Open 基于 Llama 3.1 8B 的開源模型,Deepseek 也強(qiáng)調(diào)目前使用的是一個(gè)較小的基座模型,還無法完全釋放長(zhǎng)思維鏈的潛力。
" 一個(gè)大概率會(huì)確定的事情是,在訓(xùn)練 RL 的階段,我們所需要的算力可能并不比預(yù)訓(xùn)練要少,這可能是一個(gè)非共識(shí)。" 談及 o1 時(shí),階躍星辰 CEO 姜大昕曾經(jīng)提到過這個(gè)問題。
未來的大模型不應(yīng)該花費(fèi)大量精力在簡(jiǎn)單的問題上,要想跑出真正能夠釋放思維鏈能力的模型,還需要一定時(shí)間。
突破 AGI 二階段,國(guó)內(nèi)加速探索產(chǎn)品落地
大廠們?yōu)槭裁磳?o1 視為了下一個(gè)必備項(xiàng)?
在 OpenAI 和智譜給出的 " 通往 AGI 五階段 " 的定義中,兩家公司均將多模態(tài)和大語言模型能力歸在 L1 階段,也就是最為基礎(chǔ)的能力配備。
而 o1 的出現(xiàn),則標(biāo)志著大模型能力突破到了 L2 階段。自此,大模型開始真正擁有了邏輯思維能力,在無人力干預(yù)的情況下進(jìn)行規(guī)劃、驗(yàn)證和反思。
當(dāng)下,雖然海外以 OpenAI 為代表,率先實(shí)現(xiàn)了 " 慢思考 " 大模型能力的實(shí)現(xiàn),但國(guó)內(nèi)廠商在后續(xù)追趕的思路上想的更多。在同步跟進(jìn) o1 類產(chǎn)品的同時(shí),大模型公司們已經(jīng)在思考如何將 o1 的能力和現(xiàn)有 AI 應(yīng)用方向結(jié)合。
針對(duì)大模型訓(xùn)練進(jìn)展停滯的疑慮,可以看到,在數(shù)據(jù)枯竭的情況下,o1 能夠?yàn)?Scaling Law 提供新的支撐。
此前,大模型訓(xùn)練已經(jīng)走入了 " 無數(shù)據(jù)可用 " 的困境。當(dāng)可用的優(yōu)質(zhì)數(shù)據(jù)資源變得越來越有限,給依賴大量數(shù)據(jù)進(jìn)行訓(xùn)練的 AI 大模型帶來了挑戰(zhàn)。
更多大模型公司的加入,或?qū)⒙?lián)手探索出更大的可能性。"o1 已經(jīng) scale 到了一個(gè)很大的規(guī)模,我認(rèn)為它帶來了一個(gè) Scaling 技術(shù)的新范式,不妨稱之為 RL Scaling。而且 o1 還不成熟,它還是一個(gè)開端。" 姜大昕說。
在現(xiàn)有的一些 AI 應(yīng)用上,思維鏈的能力已經(jīng)幫助提升了 AI 技術(shù)的使用效果。
以智譜的 " 會(huì)反思的 AI 搜索 " 為例,結(jié)合思維鏈能力,讓 AI 能夠?qū)?fù)雜問題拆解成多個(gè)步驟,進(jìn)行逐步搜索和推理。通過聯(lián)網(wǎng)搜索 + 深度推理,再將所有答案信息綜合整理到一起,AI 能夠給到一個(gè)更加精準(zhǔn)的答案,
當(dāng)大模型開始學(xué)會(huì) " 自我思考 ",通往 L3(Agent)的大門也正在被大模型公司們推開。
" 從 L1 到 L2 花了一段時(shí)間,但我認(rèn)為 L2 最令人興奮的事情之一是它能夠相對(duì)快速地實(shí)現(xiàn) L3,我們預(yù)計(jì)這種技術(shù)最終將帶來的智能體將非常有影響力。" 談及 o1,Sam Altman 肯定了 " 慢思考 " 模型對(duì)推動(dòng)智能體發(fā)展的潛力。
在智能體的能力實(shí)現(xiàn)上,思維鏈?zhǔn)侵悄荏w功能的重要一步。應(yīng)用思維鏈能力,大模型才能對(duì)接受到的任務(wù)進(jìn)行規(guī)劃,將復(fù)雜的需求拆解成多個(gè)步驟,支撐智能體的任務(wù)規(guī)劃。
最近涌現(xiàn)的一批 " 自主智能體 " 產(chǎn)品就是 Agent 能力的突破:通過將執(zhí)行任務(wù)拆解到極致,AI 開始學(xué)會(huì)像人一樣用手機(jī)、電腦,幫助用戶完成跨應(yīng)用操作。智譜、榮耀等公司推出的智能體,已經(jīng)可以通過指令幫用戶完成點(diǎn)單購(gòu)買的任務(wù)。
但以目前的情況,開發(fā)者還需要具體結(jié)合 o1 類產(chǎn)品的能力,去調(diào)整智能體的輸出效果,讓它更接近人類的使用習(xí)慣。
在如何不過度思考的情況下,平衡大模型的推理進(jìn)化和用戶對(duì)效率的需求?這是楊植麟幾個(gè)月前在云棲大會(huì)上的提問,這個(gè)問題,還需要留給國(guó)內(nèi)大模型廠商們繼續(xù)解決。
來源:光錐智能















